Let me preface this by saying it's not a bad design, but I think improvements can be had.
While I agree with Mārtiņš Možeiko about the encryption part of the format, my main concern with the file format as proposed is perhaps a bit more fundamental still: rRES seems to be structured in a way that's perhaps too specific.
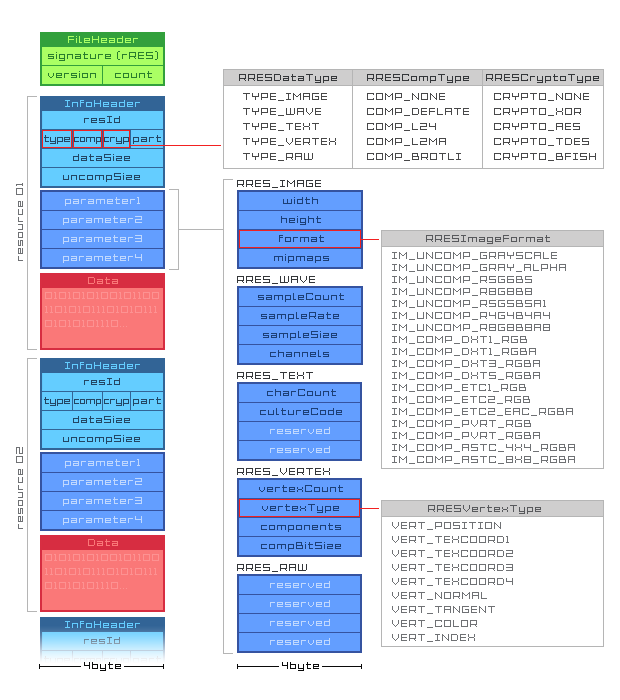
While it's certainly a good thing to specify the various types of resources, maybe having 4 parameters - which can be used or reserved for future use - isn't the best idea. What if you want to add a new type of resource that needs 5 or more parameters? What if the majority of the objects you're packing into this resource file need no parameters at all?
I don't know what the 'part' field does in type, comp, crypt, part. Maybe it's there to split up a given resource into more than 1 part? Why would you want to split up an image into more than 1 part? Or is this intended for a font with at most 256 glyphs, where each glyph is its own part?
This is one of those things that feels very specific, but where it's unclear that you're actually going to use this option field in question. Might this byte instead be used as a 'param count' or 'param bytes'? The latter would give you a bit of flexibility, where each resource can have between 0 and 255 bytes worth of params, laid out as makes sense for that resource type.
(Edit: I see now in your reply above that it stands for parts count. Might this not be a parameter? Some types of resources wouldn't be split up like this.)
You can still use the width, height, format, mipmaps for RRES_IMAGE, you'd just set param_bytes to 16.
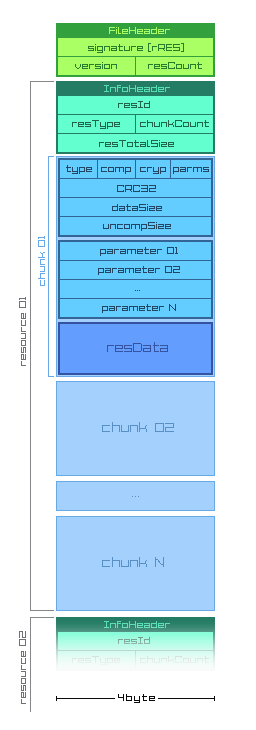
Alternatively, let the type of resource determine how many bytes of parameters directly follow the header, preceding the actual payload. If you see it's a type RRES_IMAGE, you know the next 16 bytes are parameters. If you see it's RRES_TEXT, there's only 8 bytes worth of params.
Additionally, as a resource pack file format, one thing I seem to be missing is a central directory. It seems you need to know the ID of the resource you need and keep this information elsewhere. The resource blocks themselves don't appear to have a place to store a filename or other identifier, and there's no directory in the diagram.
Perhaps a good addition would be to have the final entry be an RRES_DIRECTORY, which allows you to identify the resources by a name or some other identifier, and which has an offset into the file for the resource in question.
The last 32 bits of the file could be the directory length, so you could open the file and verify the rRES header, then seek to the end, read the directory length and jump back that many bytes and confirm you've landed on RRES_DIRECTORY. Alternatively, add a 32 bit DirectoryOffset to the FileHeader after `count`? If that DirectoryOffset == 0, it means you know what each of the resources are and can identify them by their ID in another way, with the directory omitted from the file. This would give you an optional directory.
Some ideas to ponder :)
It's not a bad design, but I think there's probably a few lessons to be learned from the RIFF format and how extensible it is, the PKZIP format and its directory structure, and Per Vognsen's
GOB (which riffs on RIFF and allows zero-copy use of assets).